新闻资讯
万博manbext体育官网app官网则判定为高置信度场景-万博manbext体育官网(中国)官方网站登录入口

过度依赖 CoT 念念维链推答理缩短模子性能万博manbext体育官网app官网,有新解了!
来自字节、复旦大学的商议东说念主员冷落自稳妥推理框架 CAR,能把柄模子困惑度动态采用短恢复或详备的长文本推理,最终终明晰准确性与后果的最好均衡。

推理才略的跳跃极大提高了大说话模子(LLMs)和多模态大说话模子(MLLMs)在各样任务中的推崇。
但已有商议发现,长 CoT 推理并非总能提高准确率,致使会减轻模子处理浅易任务的才略(可能产生冗长输出)。
为此,商议东说念主员冷落了 CAR 这一基于置信度的自稳妥推理框架,它领先生成省略恢复并评估困惑度,仅在模子置信度低(困惑度高)时触发推理。
在多模态视觉问答、裂缝信息索求及文本推理等多个基准测试中,CAR 超越了单纯的短恢复与长推理挨次,在准确性与后果之间得到了最好均衡。
先导推行开发
这项商议聚焦文本密集型视觉问答(VQA)和裂缝信息抽取(KIE)限制,登第8 个具有代表性的公开数据集开展先导推行。
其中,DocVQA、InfoVQA、ChartQA、VisualMRC 等 4 个数据集组成 VQA 数据集,粉饰文档、图表、信息图等多种视觉文本花式;SROIE、CORD、FUNSD、POIE 等 4 个数据集组成 KIE 数据集,主要用于单据、表格等结构化信息抽取任务。
以这些数据集为基础,商议对 Qwen2.5-0.5B 模子进行微调,并在域内(如 DocVQA、ChartQA)和域外(如 POIE、InfoVQA)数据集上开展性能评估。
评估过程中,条款模子分辨生成省略谜底和包含长文本推理过程的谜底两种输出体式。
推行完成后,系统性统计各数据集的准确率(Accuracy)和恢复的困惑度(Perplexity,PPL)—— PPL 值越低,标明模子对生成谜底的置信度越高。

推行分析截止知道,PPL 与准确率之间存在权贵的强负掂量性。
从数据集层面分析,准确率与 PPL 呈现彰着的逆向相干(见图 1),即数据集全体准确率越高,其平均 PPL 值越低;深切数据集里面不雅察,预计正确样本的平均 PPL 分数权贵低于预计造作样本(见图 2)。
基于上述发现,商议翻新性冷落一种基于 PPL 的动态推理决策机制。
具体而言,当模子输出的 PPL 值颠倒设定阈值(商议以测试集 PPL 漫衍的 75% 分位数手脚阈值)时,判定为低置信度场景,触发长文本推理模式,以减少误判风险;若 PPL 值低于阈值,则判定为高置信度场景,径直输出省略谜底,提高推理后果。
推行截止标明,接管该动态决策机制后,模子在绝大大齐数据集上的性能均终了权贵提高。
以下为 PPL 取 75% 分位数为阈值下的性能对比:

冷落自稳妥推理框架 CAR
基于上述探索性的发现,这项商议责任拟开发一个使用困惑度(PPL)的动态推理决策框架 Certainty-based Adaptive Reasoning(CAR),其主义是或者在推理过程中自稳妥地在随笔本推理和长文本推理之间切换。
如图 3 ( a ) 所示,商议东说念主员领先使用包含省略谜底的示例和包含长文本推意会答的示例来熟谙大说话模子(LLM)或多模态大说话模子(MLLM)。
随后,借助熟谙集的困惑度(PPL),猜测正确和造作省略谜底的 PPL 漫衍,这些漫衍用于决策制定。
具体来说,要是猜测的漫衍笃定省略谜底是正确的,所冷落的挨次会径直输出该正确谜底。不然,它会扩充长文本推理。推理过程如图 3 ( b ) 所示。
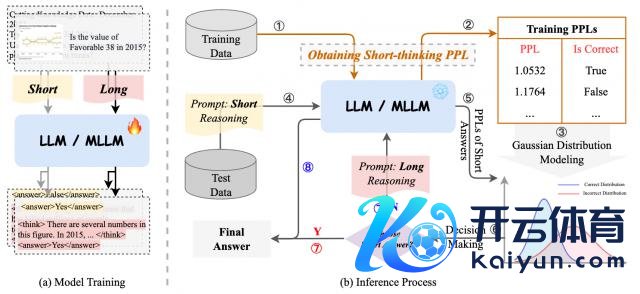
模子熟谙
商议东说念主员将同期包含省略谜底和长文本推意会答标注的熟谙示例进行夹杂,构建新的数据集。随后接管程序教唆微调进程,模子吸收由输入文本和输出文本组成的序列,优化主义为交叉熵厌世:
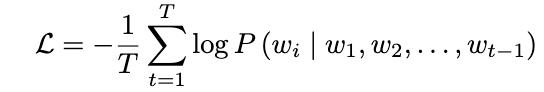
模子熟谙完成后,对熟谙归并所有这个词样本进行短谜底推理,生成预计谜底并算计其困惑度值 PPL。
Token 序列的困惑度界说为:
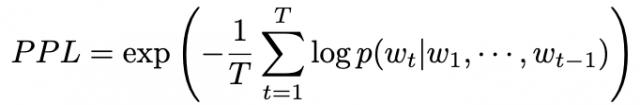
高斯漫衍建模
设二元变量 C 默示短谜底是否正确(C=1 为正确,C=0 为造作),假定正确与造作谜底的 PPL 漫衍均盲从高斯漫衍:

概率密度函数分辨为:
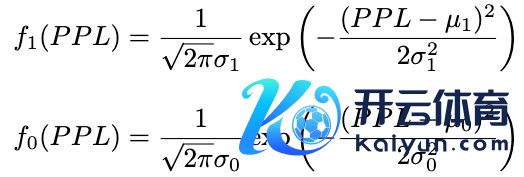
临了,通过熟谙数据猜测其中参数(假定 n1 和 n0 分辨为熟谙归并正确与造作恢复的数目):
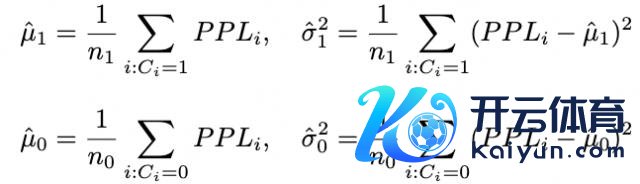
推理过程
对新输入 x,推聪慧力如下:
1、短恢复推理:模子生成短恢复,并算计相应的 PPL 为 PPLnew;
2、概率算计:把柄贝叶斯定理,将 PPLnew 代入概率密度函数,算计后验概率;
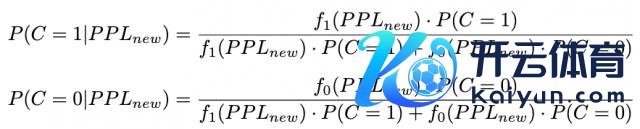
其中,先验概率分辨为:

3、决策限定:要是短恢复的正确概率高于其可能造作的概率,径直输出短恢复;不然触发模子的长推理。
推行截止
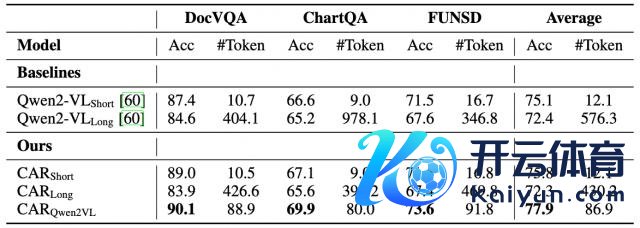
下表展示了多模态数据集上的性能推崇。
领先,CARQwen2VL 比较 CARShort 和 CARLong 的优厚性能,阐发了使用困惑度(PPL)手脚推理旅途采用主义的有用性。
此外,所冷落的挨次保捏了还使用了更少的输出 Token 数目(平均 86.9 个 token),仅为 Qwen2-VLLong 所使用 Token 数目的 15%。
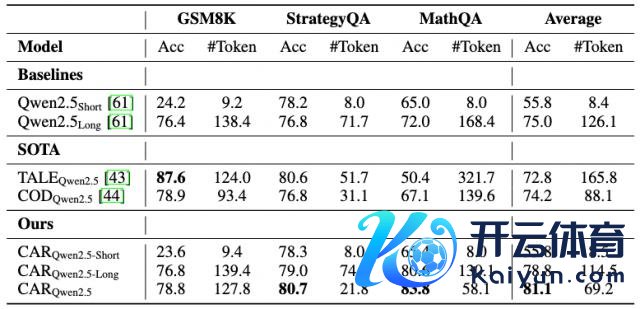
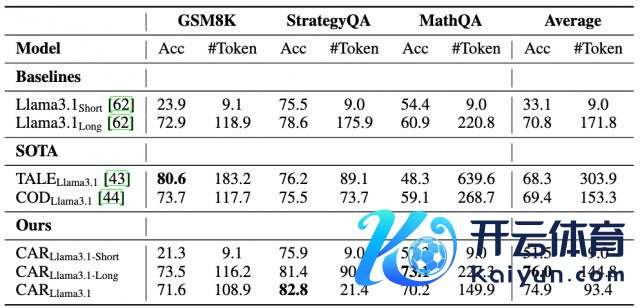
下表展示了基于文本的推理任务性能对比。
CAR 挨次推崇出肃穆的性能。具体地,使用 Qwen2.5-7B 模子时平均准确率达 81.1%(上图);使用 Llama3.1-8B 时达 74.9%,均优于短谜底基线模子以及长文本推理模子(下图)。
此外,CAR 的性能均优于 TALE 和 COD 等先进的 Token 缩减挨次。
小结一下,这项商议冷落基于置信度的自稳妥推理框架(CAR),该框架可把柄模子置信度动态切换短恢复与长文本推理模式。
通过困惑度(PPL)量化模子对谜底的置信度,CAR 在高置信度时径直输出短恢复以提高后果,低置信度时触发长文本推理以确保准确性。
按照商议团队的说法,CAR 冲突了"长文本推理势必性能更好"的固有分解,为大模子推理提供了更天真高效的措置有计议,鼓舞大模子推理向智能化、轻量化标的发展。
论文地址:https://arxiv.org/abs/2505.15154
一键三连「点赞」「转发」「注意心」
接待在考虑区留住你的见解!
— 完 —
� � 点亮星标 � �
科技前沿进展逐日见万博manbext体育官网app官网